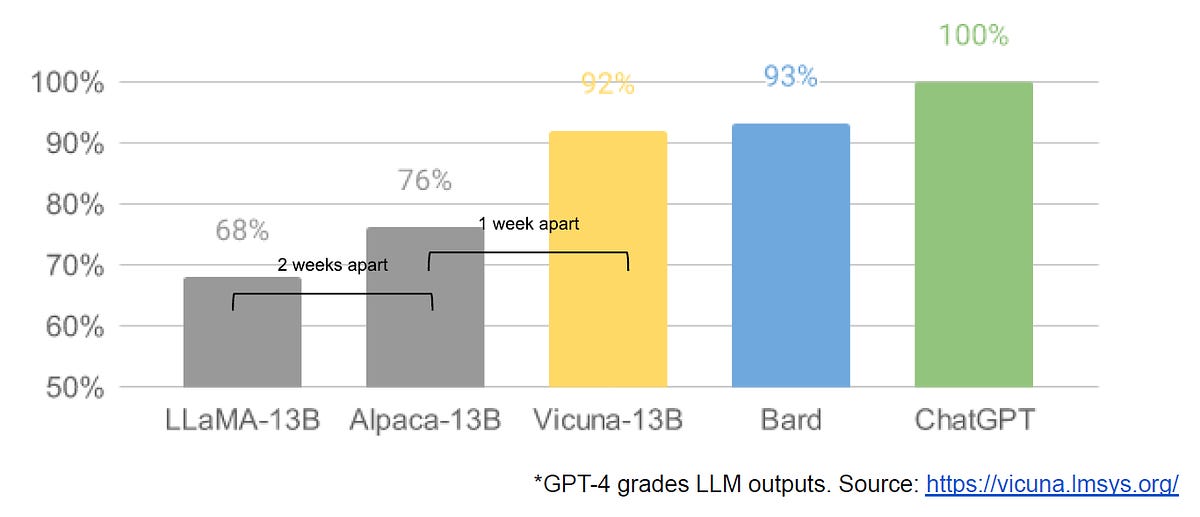
Hai că am câteva minute să scriu.

Subiectul constă în foarte puțină tehnică utilizabilă pe scară largă dar foarte mult hype, alimentat și de presa senzaționalistă și de foarte proasta înțelegere a oamenilor care știu mai multe despre AI din filmele SF decât din realitate. Se poate extinde expresia din începutul anilor '90 când se vorbea despre client/server computing, și care apoi s-a reaplicat la cloud computing, și acum la artificial intelligence: „[hype subject x] is like teenage sex - everyone talks about it, few actually do it and even fewer do it right, but everyone claims to be doing it”.
De fapt totul începe de la existența unei cantități imense de date, și dificultatea de a înțelege relațiile foarte complexe dintre ele în moduri pe care mintea umană nu le poate discerne și cataloga direct în relații de cauzalitate. De-aia mănâncă o pită toți ăia cu „s-ar putea să” și alte pompozități pentru relații aparente de corelație, însă dacă e să-i strângi cu ușa să demonstreze cauzalitatea, o dau la întors.
Vremurile când puteai înțelege că „dacă A și B sau C, atunci X” au cam trecut; acum poți avea de la zeci la mii de factori de intrare, cu sau fără legătură cu consecința, pe care nu poți aplica metoda științifică de testare experimentală pentru a determina impactul fiecărui factor când toți ceilalți sunt păstrați neschimbați. În unele domenii (life sciences de exemplu) e chiar imposibil să ții niște factori neschimbați pentru a testa efectele schimbării unuia, când toți factorii au interdependențe pe care nu le înțelegi încă, și modificarea unuia înseamnă automat modificarea altora.
Și aici intervine statistica la scară mare, mergând pe ideea e că, dacă ai un set foarte mare de date de intrare și consecințele lor, ai putea determina probabilistic care e influența fiecărui criteriu de intrare în rezultat, și ai putea calcula și marja de eroare. Iar unealta prin care poți face chestia asta este un soft prin care poți simula o „rețea neuronală” formată din „neuroni” care au mai multe intrări și o ieșire. Ieșirea unui neuron se conectează la intrările mai multor alți neuroni, și așa formează o rețea prin care se transmit impulsuri, de la stimulii dintr-o parte (datele tale de intrare) până la concluzie/consecință (ieșirea). Rețeaua asta nu face nimic corect la început, de-aia trebuie antrenată; prin asta, fiecare neuron învață ce ponderi statistice și praguri de sensibilitate să aloce fiecărui stimul, pentru a produce un semnal de ieșire. Pe ansamblu, rețeaua neuronală va învăța din setul de date de antrenament cum să proceseze un set de stimuli pentru a calcula un rezultat.
De exemplu, am avut
o lucrare de cercetare științifică (lolol) în facultate, în care am antrenat o asemenea rețea neuronală în scopuri... imobiliare. Am luat o bază de date cu niște zeci de mii de anunțuri imobiliare cu câteva zeci de caracteristici (cartier, număr de camere, etaj, suprafață, confort, cu/fără balcon, garaj, termopane, centrală, interfon, gresie și faianță, etc.), și prețul de vânzare. Am antrenat cu ea rețeaua și din asta ne-au rezultat câteva posibilități de utilizare a rețelei antrenate:
- O metodă de calcul a valorii de piață a unui apartament, furnizând combinația tuturor acestor parametri și obținând o sumă; marja de eroare statistică era și ea calculată deja. Site-ul de anunțuri imobiliare de unde am obținut baza de date putea implementa chestia asta direct pe site, ca un calculator de preț pentru apartamente.

- Un „arbore de decizie” pentru componentele valorii unui apartament pe nivele ierarhice, pornind de la cel mai important factor și determinând și care factori au o relevanță în calcul mai mică decât eroarea statistică. De exemplu: primul factor, numărul de camere. Pentru 2 camere, suma e 14k€. Pentru 3 camere, 19k€. Pentru 4 camere, 19,5k€. Al doilea factor: cartierul. Cartierul ț, adaugă 13k€. Cartierul y, scade 1,5k€. Al treilea factor: centrala. Are centrală, adaugă 10k€; n-are, scade 2k€. Al patrulea factor: garajul. N-au relevanță: dacă are rolete sau nu, dacă are faianță sau nu, dacă are interfon sau nu. Din toate astea îți iese o sumă de valoare; dacă prețul cerut de vânzător e mai mare, recomandarea ar fi să nu cumperi.
- O informație interesantă pentru cine și-a făcut un business din cumpărat apartamente vechi ca să le renoveze și să le revândă: în ce merită să investească (centrală de apartament și termopane) și cât câștigă la preț la vânzare, și în ce nu merită investiția fiindcă nu influențează prețul (faianță, interfon).
Cifrele sunt scoase din burtă, dar ați prins ideea.
Cu cât setul de date de antrenament este mai bogat, cu atât mai bun devine modelul statistic obținut prin antrenarea rețelei neuronale. De exemplu, acu' 21 de ani, facultatea americană unde eram avea un parteneriat cu spitalul local specializat în detecția și tratamentul cancerului, prin care săptămânal făceau un data dump de la tomograf într-un cluster de 40 de workstation-uri Sun al facultății. De câțiva ani era în antrenament o rețea neuronală ce lua ca date de intrare imaginile de la tomograf și diagnosticul dat de medic - e sau nu e cancer, pentru a ajunge cu rețeaua neuronală la o eroare statistică cel puțin la fel de bună cu cea a medicilor, pentru ca să-i dai o radiografie și sistemul să-ți zică „e cancer incipient, eroarea e de 4%”.
N-am idee unde e proiectul acum, dar de câțiva ani se vorbea de posibilitatea de a agrega simptomele și informațiile medicale despre un pacient pentru a sugera medicului diagnostice probabile. Complexitatea e încă foarte ridicată pentru a face asta cu o marjă de eroare mică, DAR știu sigur că industria asigurărilor medicale folosește aceste date pentru a calcula factorul de risc și a decide cât să ceară fiecărui client să plătească lunar pentru ca să iasă pe profit când unii ajung în spitale sau cimitir.
Inteligența artificială nu e decât un pas înainte al acestor modele statistice. Sunt softuri (comerciale) care vin deja cu diverse chestii antrenate și tot ce trebuie să faci e să-i dai datele de intrare pentru ca să-ți iasă anumite rezultate. Dar e în interesul producătorilor să îți folosească datele pentru a alimenta în continuare antrenamentul rețelelor neuronale și a îmbunătăți continuu marja de eroare. De-aia Google e foarte fericit să ofere free photo storage ca să aibă material cu care să facă face recognition pe pozele oamenilor. De-aia Amazon înregistrează voice snippets ca să-și antreneze voice recognition la Alexa, și le leagă de tracking info și detalii financiare pentru ca să-și antreneze precizia cu care identifică nevoile tale și să-ți propună să cumperi chestii chiar înainte să-ți dai seama conștient că vrei sau îți trebuie ceva. Există chat bots pentru first level user interface, fie text pe vreun site, fie vocal în robot telefonic. Vodafone și ING au așa ceva de câțiva ani. Companiile de electricitate americane bagă pe gâtul consumatorilor contoare electrice care fac data logging pentru consum pentru a putea genera la scară națională pattern-uri cu care să echilibreze consumul cu producția/achiziția și prețul.
Dar inteligența artificială nu este decât o denumire pompoasă pentru un algoritm statistic foarte, foarte complex, și a cărei rată de eroare depinde de cât de multe date de antrenament poate să obțină pentru antrenament. Nu poate face singur inferențe și generalizări, nu poate să-și asume riscuri și să ia inițiativa să testeze chestii „what if”, e pur și simplu un model statistic determinist. Poate genera cunoștințe noi și descoperi relații de corelație/cauzalitate în date pe care mintea umană nu le poate procesa, însă doar dacă acele date există și în cantități atât de mari încât marja statistică să fie mică. Sau dacă datele sunt corecte/sanitizate. Au făcut unii un experiment antrenând un AI cu texte de pe reddit și 4chan și, guess what, a ieșit un chat bot depresiv și suicidal și care insulta în stânga și dreapta. Oopsies.
Garbage in, garbage out. Toată inteligența asta artificială n-are filtru propriu și lucrează exclusiv cu materialul clientului.